
INTRODUCTION
Named Entity Recognition (NER) is integral to many NLP applications. It is the task of identifying named entity mentions in unstructured text and classifying them to predefined classes such as person, organization, location, or date. Due to the scarcity of Arabic resources, most of the research on Arabic NER focuses on flat entities and addresses a limited number of entity types (person, organization, and location). The goal of this shared task is to alleviate this bottleneck by providing Wojood, a large and rich Arabic NER corpus. Wojood consists of about 550K tokens (MSA and dialect, in multiple domains) that are manually annotated with 21 entity types.
The following is the list of entity types annotated:
- Person (PERS)
- Group of people, nationalities, religious, political groups (NORP)
- Occupation or professional title (OCC)
- Organization (ORG)
- Geopolitical Entity (GPE)
- Geographical Location (LOC)
- Facility, landmark, or place (FAC)
- Event
- Date
- Time
- Language
- Website
- Law
- Product
- Cardinal
- Ordinal
- Quantity
- Unit
- Money
- Currency
The corpus and annotation guidelines are fully explained in the article Wojood: Nested Arabic Named Entity Corpus and Recognition using BERT.
For this shared task, we offer two versions of Wojood:
Wojood-Flat: in this annotation scheme, each token is assigned only one entity type. For instance, in the sentence “I work at Cairo Bank”, “Cairo Bank” is annotated as ORG.
Wojood-Nested: contains nested entities, which are entities that overlap. For example, in the sentence “I work at Cairo Bank”, “Cairo Bank” is annotated with ORG and “Cairo” is annotated with GPE. Unlike the flat NER, in the nested scheme some tokens will have more than one entity type assigned to it (see figure below).
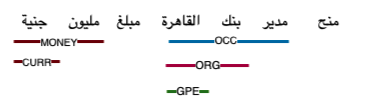

While we invite participation to either of the two subtasks, we hope that teams will submit models to both tasks. By offering two sub-tasks, we hope the research community will offer diverse machine learning architectures, including sequence to sequence modeling, multi-task learning, transfer learning, and graph models. For this shared task, we provide train, development, and test splits different from our article. Therefore, different results are expected. The new splits are selected proportionally to the domain distribution, in other words, we maintain the same domain distribution in each data split.
SHARED TASK
As described, this shared task targets both flat and nested Arabic NER. The subtasks are:
Subtask 1: Flat NER
In this subtask, we provide the Wojood-Flat train (70%) and development (10%) datasets. The final evaluation will be on the test set (20%). The flat NER dataset is the same as the nested NER dataset in terms of train/test/dev split and each split contains the same content. The only difference in the flat NER is each token is assigned one tag, which is the first high-level tag assigned to each token in the nested NER dataset.
Subtask 2: Nestd NER
In this subtask, we provide the Wojood-Nested train (70%) and development (10%) datasets. The final evaluation will be on the test set (20%).
METRICS
The evaluation metrics will include precision, recall, F1-score. However, our official metric will be the micro F1-scoreM/b>.
The evaluation of shared tasks will be hosted through CODALAB. Teams will be provided with a CODALAB link for each shared task.
-CODALAB link for NER Shared Task Subtask 1 (Flat NER)
-CODALAB link for NER Shared Task Subtask 2 (Nestd NER)
BASELINES
Two baseline models trained on Wojood (flat and nested) are provided:
Nested NER baseline: is presented in this article, and code is available in GitHub. For the shared task, the baseline is based on the micro-F1 score averaged across three seeds, resulting in an average micro-F1 of 0.9047 and standard deviation of 0.0051 (note that this baseline does not handle nested entities of the same type).
Flat NER baseline: same code repository for nested NER (GitHub) can also be used to train flat NER task. For the shared task, the baseline is based on the micro-F1 score averaged across three seeds, resulting in an average micro-F1 of 0.8681 and standard deviation of 0.0045.
| Subtask | Average Micro-F1 | Standard Deviation |
|---|---|---|
| Wojood flat entity annotations (Subtask 1) | 0.8681 | 0.0045 |
| Wojood nested entity annotations (Subtask 2) | 0.9047 | 0.0051 |
GOOGLE COLAB NOTEBOOKS
To allow you to experiment with the baseline, we authored four Google Colab notebooks that demonstrate how to train and evaluate our baseline models.
[1] Train Flat NER: This notebook can be used to train our ArabicNER model on the flat NER task using the sample Wojood data found in our repository.
[2] Evaluate Flat NER: This notebook will use the trained model saved from the notebook above to perform evaluation on unseen dataset.
[3] Train Nested NER: This notebook can be used to train our ArabicNER model on the nested NER task using the sample Wojood data found in our repository.
[4] Evaluate Nested NER: This notebook will use the trained model saved from the notebook above to perform evaluation on unseen dataset..
SUBMISSION DATA FORMAT
Your submission to the task will include one file, which is the prediction of your model in the CoNLL format. If you are submitting to both subtasks, then you will have two submissions. The CoNLL file should include multiple columns space-separated. The IOB2 scheme should be used for the submission, which is the same format used in the Wojood dataset. Do not include a header in your submitted file. Segments should be separated by a blank line as in the sample data found in the repository.
Note that we will validate your submission to verify the number of segments and number of tokens within each segment is the same as the test dataset. We will also verify the token on each line maps to the same token in the test dataset.
Flat NER: the first column is the token (word), and the second column is the tag (entity name).
| Column # | Value |
|---|---|
| 1 | Token |
| 2 | Tag |
Example data file
| flat_prediction.txt |
|---|
| جريدة B-ORG فلسطين I-ORG / O نيسان B-DATE ( I-DATE 26 I-DATE / I-DATE 4 I-DATE / I-DATE 1947 I-DATE ) I-DATE . O |
Nested NER: the first column is the token (word), followed by 21 columns, each column is for one entity type. The 21 columns should be in a particular order as follows:
| Column # | Value |
|---|---|
| 1 | Token |
| 2 | CARDINAL or O |
| 3 | CURR or O |
| 4 | DATE or O |
| 5 | EVENT or O |
| 6 | FAC or O |
| 7 | GPE or O |
| 8 | LANGUAGE or O |
| 9 | LAW or O |
| 10 | LOC or O |
| 11 | MONEY or O |
| 12 | NORP or O |
| 13 | OCC or O |
| 14 | ORDINAL or O |
| 15 | ORG or O |
| 16 | PERCENT tag or O |
| 17 | PERS or O |
| 18 | PRODUCT or O |
| 18 | QUANTITY or O |
| 19 | TIME or O |
| 20 | UNIT or O |
| 21 | WEBSITE or O |
Example data file
| nested_prediction.txt |
|---|
| جريدة O O O O O O O O O O O O O B-ORG O O O O O O O فلسطين O O O O O B-GPE O O O O O O O I-ORG O O O O O O O / O O O O O O O O O O O O O O O O O O O O O نيسان O O B-DATE O O O O O O O O O O O O O O O O O O ( O O I-DATE O O O O O O O O O O O O O O O O O O 26 O O I-DATE O O O O O O O O O O O O O O O O O O / O O I-DATE O O O O O O O O O O O O O O O O O O 4 O O I-DATE O O O O O O O O O O O O O O O O O O / O O I-DATE O O O O O O O O O O O O O O O O O O 1947 O O I-DATE O O O O O O O O O O O O O O O O O O ) O O I-DATE O O O O O O O O O O O O O O O O O O . O O O O O O O O O O O O O O O O O O O O O |
REGISTRATION
Participants need to register via this form (https://forms.gle/UCCrVNZ2LaPviCZS6). Participating teams will be provided with common training development datasets. No external manually labelled datasets are allowed. Blind test data set will be used to evaluate the output of the participating teams. Each team is allowed a maximum of 3 submissions. All teams are required to report on the development and test sets (after results are announced) in their write-ups.
FAQ
For any questions related to this task, please check our Frequently Asked Questions
IMPORTANT DATES
Below is subject to change:
- March 03, 2023: Registration available
- May 25, 2023: Data-sharing and evaluation on development set Avaliable
- June 10, 2023 June 30, 2023: Registration deadline (Extended)
- July 20, 2023: Test set made available
- July 30, 2023: Evaluation on test set (TEST) deadline
- September 5, 2023 September 12, 2023: Shared task system paper submissions due (Extended)
- October 12, 2023: Notification of acceptance
- October 30, 2023: Camera-ready version
- TBA: WANLP 2023 Conference.
* All deadlines are 11:59 PM UTC-12:00 (Anywhere On Earth).
CONTACT
For any questions related to this task, please contact the organizers directly using the following email address: NERSharedtask2023@gmail.com or join the google group: https://groups.google.com/g/ner_sharedtask2023.
ORGANIZERS
- Mustafa Jarrar, Birzeit University
- Muhammad Abdul-Mageed, University of British Columbia & MBZUAI
- Mohammed Khalilia, Birzeit University
- Bashar Talafha, University of British Columbia
- AbdelRahim Elmadany, University of British Columbia
- Nagham Hamad, Birzeit University
- Alaa Omer, Birzeit University